Clasificación de géneros musicales con Machine Learning y Scikit-learn
Uso de diferentes algoritmos de machine learning para clasificación, regresión y clustering en el dataset GTZAN para géneros musicales.

- 1. Introducción
- 2. Algoritmos supervisados
- 3. Algoritmos no supervisados
- 4. Ensembles
- 5. Enlace al notebook
- 6. Conclusiones
1. Introducción
El dataset GTZAN es uno de los más utilizados para estudiar problemas de clasificación musical. Consta de 1000 archivos de audio, divididos en 10 géneros (rock, pop, metal, disco, etc.).
En este proyecto se han utilizado los archivos de características (en formato CSV), con un total de 58 variables, extraídas mediante técnicas de análisis de audio como STFT, MFCC, tempo, RMS, entre otras; las cuales han sido obtenidas por Andrada en Kaggle.
A lo largo del cuaderno, se implementan técnicas de clasificación, regresión, clustering y métodos de ensamblado (ensembles), aplicando diferentes algoritmos de scikit-learn y analizando su rendimiento.
2. Algoritmos supervisados
Los algoritmos supervisados no significan que tengamos que estar encima de ellos para que aprendan, sino que el dataset se encuentra etiquetado, encontrando una variable ‘target’ sobre la que hacer clasificación o regresión.
En este caso, el género musical o el RMS de la muestra de audio.
Los modelos supervisados evaluados fueron:
- Regresión logística: Sirvió como línea base para la clasificación multiclase. A pesar de su simplicidad, logró un rendimiento competitivo.
- Support Vector Machines (SVM): Con kernel radial, obtuvo buenos resultados al separar géneros con fronteras no lineales.
- Árboles de decisión y Random Forest: Buena interpretabilidad y precisión. Random Forest mejoró la estabilidad reduciendo el sobreajuste.
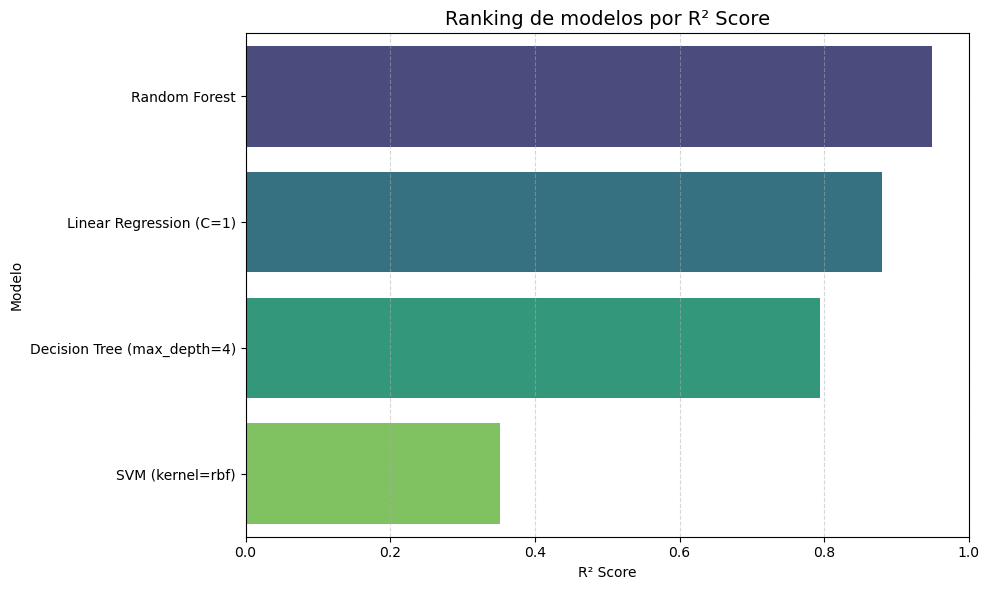 Figura 1: Ranking de regresores
Figura 1: Ranking de regresores
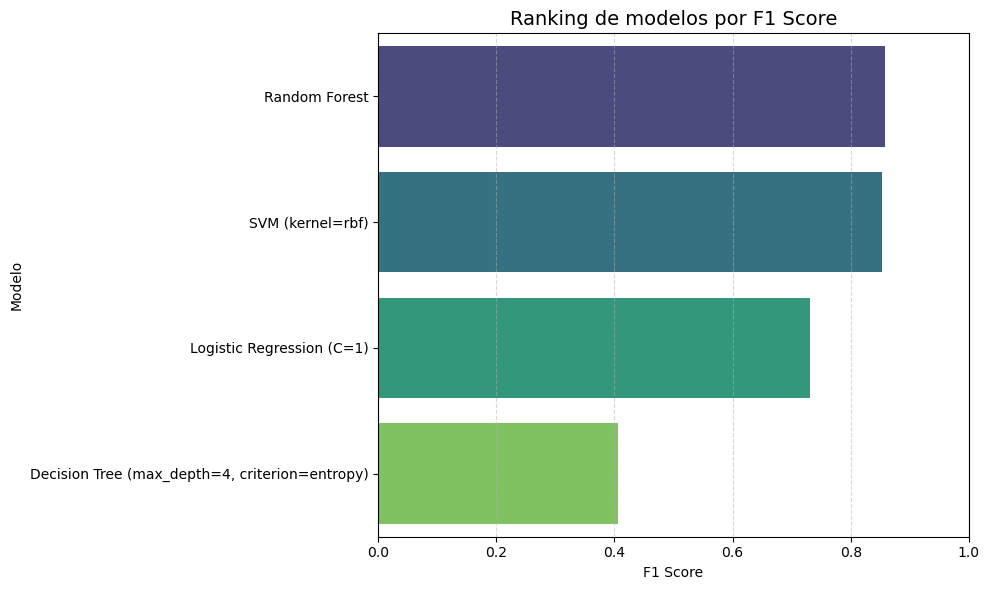 Figura 2: Ranking de clasificadores
Figura 2: Ranking de clasificadores
Además, se evaluaron los modelos mediante matrices de confusión, accuracy, F1-score y validación cruzada.
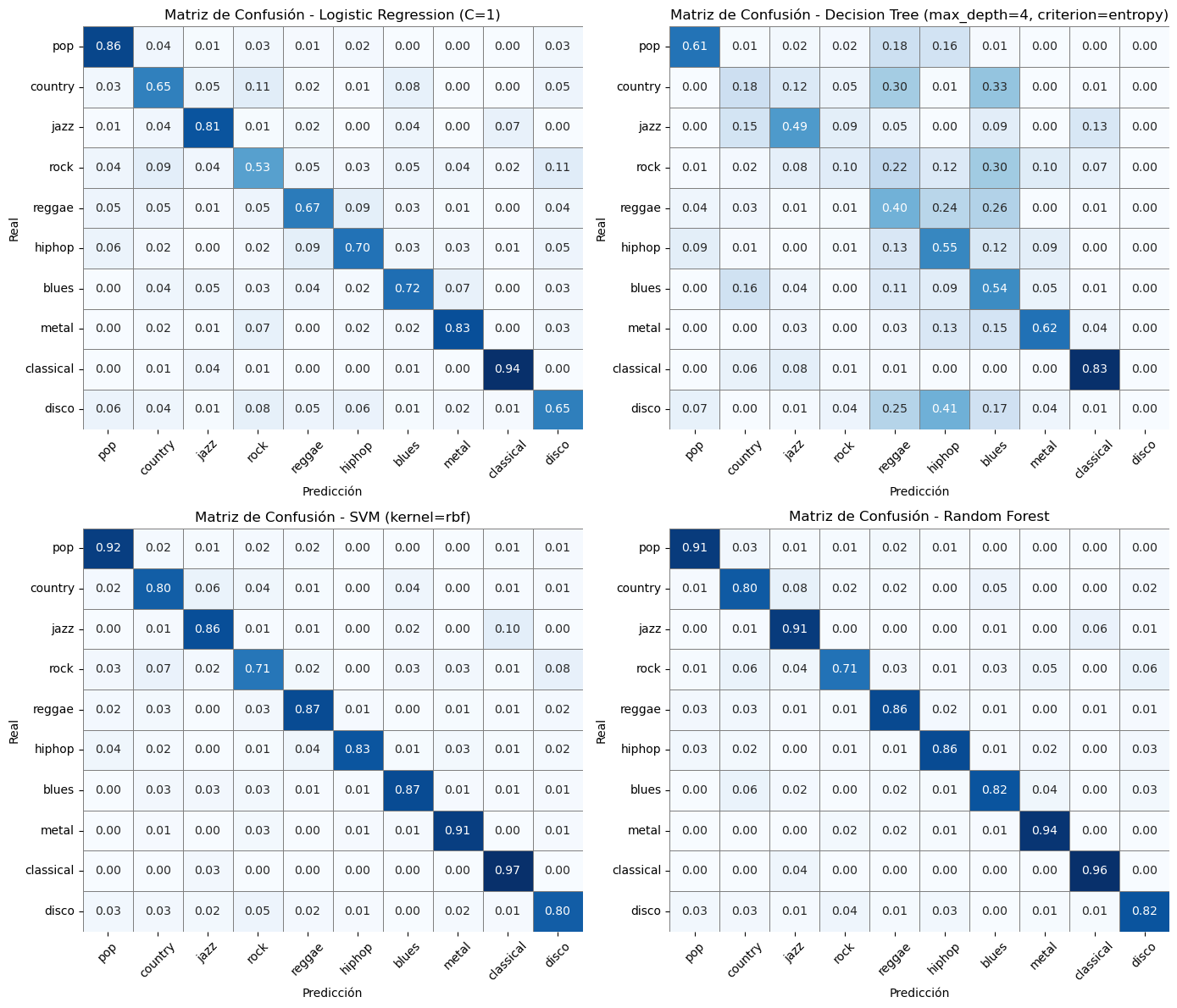 Figura 3: Matriz de confusion clasificadores
Figura 3: Matriz de confusion clasificadores
3. Algoritmos no supervisados
A diferencia de los algoritmos supervisados, los no supervisados no disponen de esta variable target, sino que dejamos que los algoritmos encuentren las relaciones intrínsecas del dataset por sí solo.
Para tareas de clustering, se aplicaron los siguientes métodos:
- K-Means: Se utilizó para intentar agrupar las muestras sin etiquetas. Aunque no se alineó perfectamente con los géneros, mostró agrupaciones consistentes.
- PCA (Análisis de Componentes Principales): Para reducción de dimensionalidad y visualización. Permitió proyectar los datos en 2D y observar agrupaciones por género.
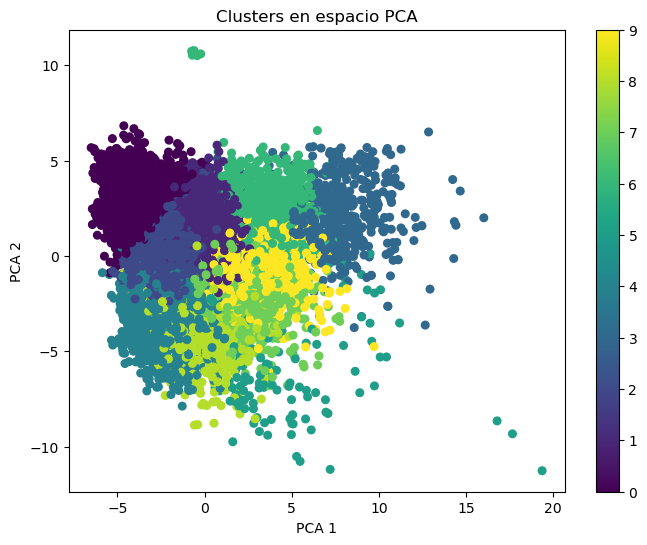 Figura 4: Visualización de clústers de k-means usando PCA
Figura 4: Visualización de clústers de k-means usando PCA
4. Ensembles
Se exploraron métodos de ensamblado para mejorar el rendimiento:
- Bagging: En Bagging se consigue reducir el sobreajuste y mejora la estabilidad frente a árboles individuales mediante la separación del dataset entre varios modelos.
- Gradient Boosting: Uno de los modelos con mejor rendimiento, aunque más costoso computacionalmente.
- AdaBoost: Al igual que el otro algoritmo de boosting, se ensamblan los modelos más pequeños secuencialmente, sin embargo, no obtuvo resultados prometedores.
- Stacking: En Stacking, se combinan las salidas de múltiples modelos, y se pasan por un
meta-modeloel cuál agrupa los output y obtiene una salida única con mejores resultados.
5. Enlace al notebook
Puedes encontrar el notebook del proyecto aquí: Kaggle
6. Conclusiones
En este estudio se han explorado técnicas de clasificación, regresión y clustering, así como algoritmos de ensemble de modelos con boosting, stacking y bagging.
A destacar es el hecho de cómo varían los resultados si utilizamos el dataset original con 1000 registros con muestras de 30 segundos versus a coger el dataset con splits de 3 segundos y 10.000 muestras.
Siendo en el primer caso imposible o muy difícil realizar tareas de clasificación o regresión debido al poco número de muestras existentes.
Los datos son el combustible de estos modelos, por lo que hay que asegurarse de nutrirlos adecuadamente.
Por último, en relación al propio dataset, hemos visto que en casi todas las tareas, los géneros que más dificultades les han presentado a los modelos son los de rock, blues y disco. Mientras que los que pertenecían a géneros como el metal o música clásica, resultaban más fáciles de distinguir del resto.